Технологии и ИИ

Илья Бердыш
12 дек. 2025 г.

11 декабря 2025 года OpenAI представила GPT-5.2 — самую продвинутую модель для профессиональной работы. Модель показывает результаты выше уровня экспертов в реальных задачах, охватывающих 44 профессии. Средний пользователь ChatGPT Enterprise экономит 40-60 минут в день, а активные пользователи — более 10 часов в неделю.
GPT-5.2 устанавливает новые рекорды: 70.9% побед над профессионалами на GDPval, 55.6% на SWE-Bench Pro, 100% на AIME 2025, 90.5% на ARC-AGI-1. Три версии модели доступны: Instant для быстрой работы, Thinking для сложных задач, Pro для максимального качества.

В этом руководстве разберём ключевые возможности GPT-5.2, результаты на профессиональных задачах, улучшения в программировании и как модель меняет подход к работе с AI.
Что такое GPT-5.2 от OpenAI
GPT-5.2 — самая продвинутая серия моделей OpenAI для профессиональной работы со знаниями. Модель разработана для создания электронных таблиц, презентаций, написания кода, анализа изображений, понимания длинных контекстов и обработки сложных многоэтапных проектов. Это первая модель OpenAI, работающая на уровне или выше человека-эксперта.
GPT-5.2 Thinking побеждает или сравнивается с топовыми профессионалами в 70.9% сравнений на задачах GDPval по оценкам экспертных судей. Модель производит результаты более чем в 11 раз быстрее и менее чем за 1% стоимости экспертов. Компании Notion, Box, Shopify, Harvey и Zoom отметили передовую производительность в долгосрочных рассуждениях.
Три версии GPT-5.2:
Instant — быстрая модель для ежедневной работы с улучшенным разговорным тоном
Thinking — для глубокой работы над сложными задачами с детальными рассуждениями
Pro — самый умный вариант для критически важных задач где важно максимальное качество
Ключевые улучшения GPT-5.2
GPT-5.2 приносит значительные улучшения в общем интеллекте, понимании длинного контекста, агентном вызове инструментов и зрении. Модель лучше выполняет сложные реальные задачи от начала до конца чем любая предыдущая модель.
Основные улучшения:
Профессиональные задачи: 70.9% побед над экспертами на GDPval (44 профессии)
Программирование: 55.6% на SWE-Bench Pro, 80% на SWE-bench Verified
Математика: 100% на AIME 2025, 40.3% на FrontierMath Tier 1-3
Длинный контекст: близко к 100% точности на 4-needle MRCR до 256K токенов
Зрение: ошибки сокращены вдвое на диаграммах и интерфейсах
Галлюцинации: на 30% меньше ошибок (6.2% против 8.8% у GPT-5.1)
Абстрактное рассуждение: 90.5% на ARC-AGI-1, 54.2% на ARC-AGI-2
Databricks, Hex и Triple Whale нашли модель исключительной для агентной науки о данных и анализа документов. Cognition, Warp, Charlie Labs, JetBrains и Augment Code заявляют о передовой производительности кодирования с измеримыми улучшениями в интерактивном программировании, ревью кода и поиске багов.
Результаты на профессиональных задачах — GDPval
GPT-5.2 устанавливает новый рекорд на GDPval — оценке измеряющей хорошо определённые задачи работы со знаниями в 44 профессиях из топ-9 индустрий США. Задачи запрашивают реальные рабочие продукты: презентации продаж, бухгалтерские таблицы, графики срочной помощи, производственные диаграммы, короткие видео.
GPT-5.2 Thinking побеждает или сравнивается с топовыми профессионалами в 70.9% сравнений. Один судья GDPval прокомментировал: "Захватывающий и заметный скачок в качестве... кажется что это сделано профессиональной компанией со штатом, имеет удивительно хорошо разработанный макет."
Результаты GDPval (победы или ничьи против профессионалов):
GPT-5.2 Pro: 74.1% — новый максимум
GPT-5.2 Thinking: 70.9% — первая модель на уровне эксперта
GPT-5 Thinking: 38.8% — предыдущее поколение
На внутреннем тесте задач моделирования электронных таблиц младшего аналитика инвестиционного банкинга средний балл GPT-5.2 Thinking вырос на 9.3%: с 59.1% до 68.4%. Задачи включают составление трёхзаявочных моделей для Fortune 500 компаний с правильным форматированием и цитатами, или построение модели выкупа с левериджем для приватизации.
Программирование — 55.6% на SWE-Bench Pro
GPT-5.2 Thinking устанавливает новый рекорд 55.6% на SWE-Bench Pro — строгой оценке программной инженерии в реальном мире. В отличие от SWE-bench Verified (только Python), SWE-Bench Pro тестирует четыре языка и более устойчив к загрязнению, сложен, разнообразен и промышленно релевантен.
На SWE-bench Verified модель достигает 80% — нового максимума OpenAI. Для повседневного использования это модель, которая более надёжно отлаживает производственный код, реализует запросы функций, рефакторит большие кодовые базы и отправляет исправления от начала до конца с меньшим ручным вмешательством.
Результаты на программировании:
SWE-Bench Pro (public): 55.6% (GPT-5.1: 50.8%)
SWE-bench Verified: 80.0% (GPT-5.1: 76.3%)
SWE-Lancer IC Diamond: 74.6% (GPT-5.1: 69.7%)
Фронтенд разработка и сложные UI
GPT-5.2 Thinking значительно сильнее в фронтенд разработке и сложной или нестандартной UI работе — особенно с 3D элементами. Ранние тестеры отметили это как мощного ежедневного партнёра для инженеров. Модель может создавать сложные интерактивные приложения из одного промпта: симуляцию океанских волн с настройками, конструктор праздничных открыток, игры. Всё в одном HTML файле.
Отзывы от компаний-разработчиков:
"GPT-5.2 представляет самый большой скачок для моделей GPT в агентном программировании с GPT-5 и является передовой моделью кодирования в своём ценовом диапазоне. Версионный скачок недооценивает прыжок в интеллекте." — Jeff Wang, CEO, Windsurf
Снижение галлюцинаций на 30%
GPT-5.2 Thinking галлюцинирует меньше чем GPT-5.1 Thinking. На наборе деидентифицированных запросов из ChatGPT ответы с ошибками были на 30% относительно менее распространены. Для профессионалов это означает меньше ошибок при использовании модели для исследований, написания, анализа и поддержки решений.
Уровень ошибок на уровне ответа: GPT-5.2 Thinking — 6.2% ответов с хотя бы одной ошибкой, GPT-5.1 Thinking — 8.8%. Как все модели, GPT-5.2 Thinking несовершенна. Для критически важных задач перепроверяйте ответы.
Улучшение точности:
30% относительное снижение ошибок
6.2% против 8.8% ответов с ошибками
Меньше галлюцинаций при исследованиях и анализе
Более надёжна для принятия решений
Длинный контекст — 256K токенов с высокой точностью
GPT-5.2 Thinking устанавливает новый рекорд в рассуждениях с длинным контекстом. Это первая модель достигающая близко к 100% точности на варианте 4-needle MRCR до 256K токенов. Модель может работать с длинными документами — отчётами, контрактами, исследовательскими статьями, транскриптами и многофайловыми проектами — сохраняя связность и точность.
Для задач требующих размышлений за пределами максимального контекстного окна, GPT-5.2 Thinking совместима с новой конечной точкой Responses /compact, которая расширяет эффективное контекстное окно. Это позволяет справляться с более тяжёлыми инструментами, долгосрочными рабочими процессами.
Возможности длинного контекста:
Близко к 100% точности на 4-needle MRCR до 256K токенов
Глубокий анализ документов с сотнями тысяч токенов
Синтез информации из множества источников
Поддержка сложных многоисточниковых рабочих процессов
Расширение через /compact endpoint для агентных задач
Улучшенное зрение — ошибки сокращены вдвое
GPT-5.2 Thinking — самая сильная модель зрения OpenAI, сокращающая уровни ошибок примерно наполовину на рассуждениях по диаграммам и понимании программных интерфейсов. Модель может более точно интерпретировать дашборды, скриншоты продуктов, технические диаграммы и визуальные отчёты.
GPT-5.2 имеет более сильное понимание того как элементы расположены внутри изображения. Модель может идентифицировать компоненты на изображении (например, материнскую плату) и возвращать метки с приблизительными ограничивающими рамками даже на низкокачественных изображениях.
Результаты на зрении:
CharXiv Reasoning (с Python): 88.7% (GPT-5.1: 80.3%)
ScreenSpot-Pro (с Python): 86.3% (GPT-5.1: 64.2%)
Video MMMU (без инструментов): 85.9% (GPT-5.1: 82.9%)
MMMU Pro (с Python): 80.4% (GPT-5.1: 79.0%)
Вызов инструментов — 98.7% на Tau2-bench
GPT-5.2 Thinking достигает 98.7% на Tau2-bench Telecom, демонстрируя способность надёжно использовать инструменты в длинных многошаговых задачах. Для профессионалов это более сильные рабочие процессы от начала до конца: решение кейсов поддержки, извлечение данных из множества систем, запуск анализов, генерация финальных выходов.
Когда пользователь задаёт сложный вопрос обслуживания клиентов требующий многошагового решения, модель эффективно координирует полный рабочий процесс. Например: путешественник сообщает о задержанном рейсе, пропущенной пересадке, ночёвке в Нью-Йорке и медицинском требовании к месту. GPT-5.2 управляет всей цепочкой: перебронирование, место со специальной помощью, компенсация.
Результаты на вызове инструментов:
Tau2-bench Telecom: 98.7% (GPT-5.1: 95.6%)
Tau2-bench Retail: 82.0% (GPT-5.1: 77.9%)
BrowseComp: 77.9% для Pro (GPT-5.1: 50.8%)
Scale MCP-Atlas: 60.6% (GPT-5.1: 44.5%)
Наука и математика — 100% на AIME 2025
GPT-5.2 Pro и GPT-5.2 Thinking — лучшие модели в мире для помощи учёным. На GPQA Diamond (Google-proof Q&A тест уровня выпускника) GPT-5.2 Pro достигает 93.2%, за ней следует Thinking с 92.4%. На FrontierMath Tier 1-3 модель устанавливает новый рекорд: 40.3% решённых проблем экспертного уровня.
На AIME 2025 обе версии достигают 100% — абсолютного максимума. На HMMT February 2025 модели показывают 99.4% (Thinking) и 100% (Pro). Модели начинают значимо ускорять прогресс в математике и науке. В недавней работе с GPT-5.2 Pro исследователи исследовали открытый вопрос в теории статистического обучения, модель предложила доказательство, проверенное авторами и внешними экспертами.
Результаты на науке и математике:
GPQA Diamond: 93.2% для Pro, 92.4% для Thinking
AIME 2025: 100% для обеих версий
HMMT Feb 2025: 100% для Pro, 99.4% для Thinking
FrontierMath Tier 1-3: 40.3%
HLE (с поиском): 50.0% для Pro, 45.5% для Thinking

ARC-AGI 2 — первая модель выше 90%
На ARC-AGI-1 (Verified) GPT-5.2 Pro — первая модель пересекающая порог 90%, улучшаясь с 87% у o3-preview при снижении стоимости достижения этой производительности примерно в 390 раз. На ARC-AGI-2 (Verified), который повышает сложность и лучше изолирует текучее рассуждение, GPT-5.2 Thinking достигает 52.9%. GPT-5.2 Pro работает ещё выше: 54.2%.
Улучшения отражают более сильное многошаговое рассуждение GPT-5.2, большую количественную точность и более надёжное решение проблем на сложных технических задачах.
Результаты на абстрактном рассуждении:
ARC-AGI-1 (Verified): 90.5% для Pro (первая выше 90%), 86.2% для Thinking
ARC-AGI-2 (Verified): 54.2% для Pro, 52.9% для Thinking
Стоимость снижена в 390 раз по сравнению с o3-preview
Для кого подходит GPT-5.2
GPT-5.2 создана для профессионалов, работающих со сложными задачами. Разработчики оценят рекордную производительность на SWE-Bench Pro (55.6%) и SWE-bench Verified (80%). Модель надёжно отлаживает код, реализует запросы функций, рефакторит кодовые базы от начала до конца.
Аналитики данных и финансисты найдут мощного помощника для создания электронных таблиц и моделей. На задачах младшего аналитика инвестиционного банкинга модель показывает 68.4% (рост на 9.3%). Модель создаёт трёхзаявочные модели для Fortune 500 компаний с правильным форматированием.
Целевая аудитория GPT-5.2:
Разработчики — 80% на SWE-bench, сильный фронтенд, 3D элементы
Финансисты — модели таблиц, презентации, финансовый анализ
Учёные — 93.2% на GPQA, 100% на AIME, помощь в исследованиях
Data scientists — агентный анализ данных, длинные документы
Менеджеры — создание презентаций, отчётов, планирование проектов
Профессионалы знаний — 70.9% побед над экспертами в 44 профессиях
Учёные получат лучшую модель для ускорения исследований: 93.2% на GPQA Diamond, 100% на AIME 2025, 40.3% на FrontierMath. Модель может предлагать доказательства для проверки экспертами. Менеджеры проектов и бизнес-профессионалы оценят создание презентаций, электронных таблиц, планирование на уровне или выше экспертов.
mymeet.ai для записи и анализа встреч с ИИ
GPT-5.2 показывает как AI становится мощным инструментом для профессиональной работы. Но для деловых встреч и командной работы нужны специализированные решения, оптимизированные под конкретные задачи бизнеса.

mymeet.ai — ИИ-ассистент для онлайн-встреч. Система автоматически записывает созвоны, создаёт транскрипты с определением говорящих и генерирует структурированные отчёты с ключевыми решениями и задачами.
Что умеет mymeet.ai:
Автоматическая запись — Zoom, Google Meet, Microsoft Teams, Яндекс.Телемост
Точная транскрипция — 95% точность для русского, поддержка 73 языков
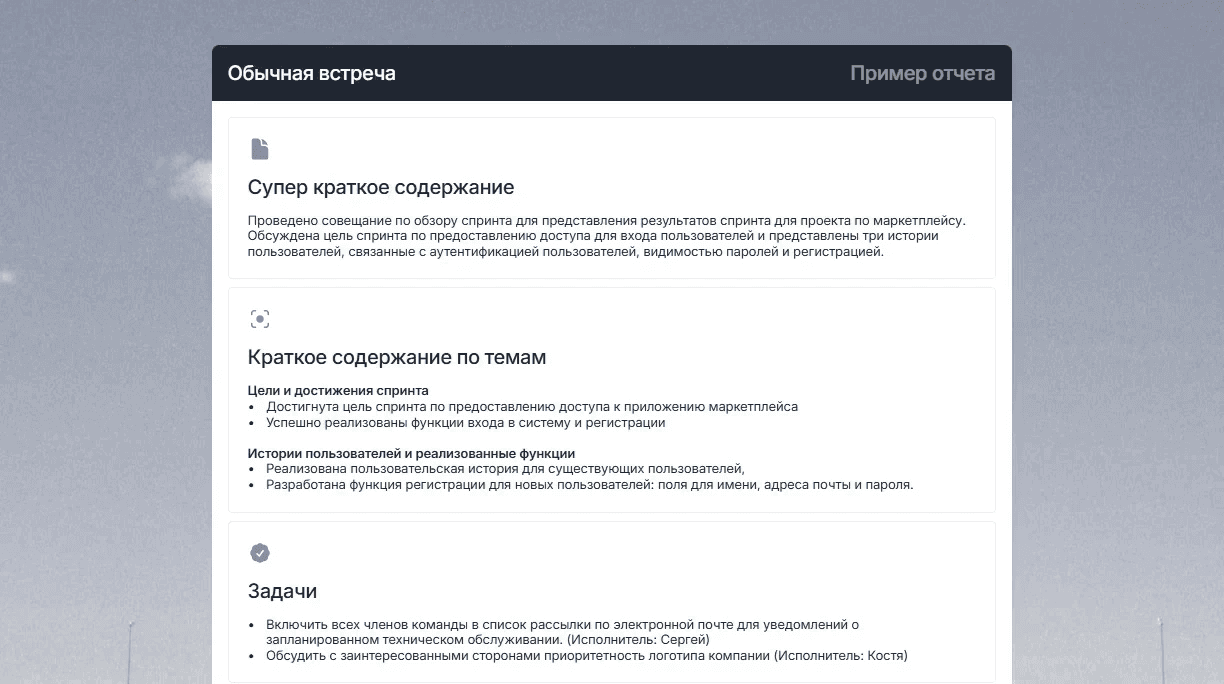
ИИ-отчёты — структурированные итоги с решениями, задачами, следующими шагами

Умный поиск — найдите что обсуждали на любой встрече через вопросы к ИИ
Интеграции — синхронизация с календарём, отправка отчётов в CRM
Безопасность — данные в России, соответствие 152-ФЗ
Экспорт — DOCX, PDF, JSON форматы
Кейс: Команда продаж проводила 30-40 встреч с клиентами еженедельно. Ручное ведение записей занимало 10-15 часов. После внедрения mymeet.ai процесс автоматизировался: система записывала встречи, создавала транскрипты, генерировала отчёты с возражениями клиентов, автоматически отправляла итоги в CRM. Время на документирование сократилось до нуля.
Попробуйте mymeet.ai бесплатно — 180 минут обработки без привязки карты. Начать →
Доступность и цены GPT-5.2
В ChatGPT GPT-5.2 (Instant, Thinking, Pro) начинает раскатываться 11 декабря, начиная с платных планов (Plus, Pro, Go, Business, Enterprise). OpenAI развёртывает GPT-5.2 постепенно для плавности и надёжности. GPT-5.1 будет доступна платным пользователям три месяца под legacy моделями.
В API GPT-5.2 Thinking доступна сегодня в Responses API и Chat Completions API как gpt-5.2, GPT-5.2 Instant как gpt-5.2-chat-latest. GPT-5.2 Pro доступна в Responses API как gpt-5.2-pro. Разработчики могут устанавливать параметр reasoning в GPT-5.2 Pro, обе версии поддерживают новый пятый уровень reasoning effort — xhigh.
Цены за миллион токенов:
gpt-5.2 / gpt-5.2-chat-latest: $1.75 вход, $0.175 кэш, $14 выход
gpt-5.2-pro: $21 вход, $168 выход
gpt-5.1 / gpt-5.1-chat-latest: $1.25 вход, $0.125 кэш, $10 выход
Ключевые детали цен:
Подписка ChatGPT остаётся по той же цене
В API GPT-5.2 дороже за токен чем GPT-5.1 (более способная модель)
90% скидка на кэшированные входы
Цена ниже других frontier моделей
Несмотря на большую стоимость за токен, стоимость достижения данного уровня качества ниже благодаря токен-эффективности
OpenAI не планирует deprecated GPT-5.1, GPT-5 или GPT-4.1 в API и сообщит о любых планах с достаточным уведомлением. Хотя GPT-5.2 будет хорошо работать из коробки в Codex, ожидается релиз версии GPT-5.2 оптимизированной для Codex в ближайшие недели.
Плюсы и минусы GPT-5.2
GPT-5.2 устанавливает новые стандарты в профессиональной работе с AI, но имеет свои сильные стороны и ограничения. Взвешенная оценка помогает понять когда модель подходит лучше всего.
Плюсы GPT-5.2:
✅ Уровень эксперта на профессиональных задачах — 70.9% побед над профессионалами в 44 профессиях
✅ Рекордное программирование — 55.6% на SWE-Bench Pro, 80% на SWE-bench Verified
✅ Снижение галлюцинаций на 30% — 6.2% ответов с ошибками против 8.8% у GPT-5.1
✅ Абсолютный максимум на математике — 100% на AIME 2025, 40.3% на FrontierMath
✅ Первая модель выше 90% на ARC-AGI-1 — 90.5% при снижении стоимости в 390 раз
✅ Длинный контекст до 256K — близко к 100% точности, глубокий анализ документов
✅ Улучшенное зрение — ошибки сокращены вдвое на диаграммах и интерфейсах
Минусы GPT-5.2:
⚠️ Выше цена за токен — $1.75 против $1.25 у GPT-5.1 (хотя стоимость качества ниже)
⚠️ Требует платную подписку ChatGPT — Plus, Pro, Go, Business или Enterprise
⚠️ Сложные генерации занимают минуты — особенно для таблиц и презентаций
⚠️ Постепенный раскат — не все увидят сразу, нужно пробовать позже
⚠️ GPT-5.1 будет удалена через 3 месяца — из ChatGPT (остаётся в API)
⚠️ Известные проблемы с over-refusals — OpenAI работает над улучшением
⚠️ Pro версия самая дорогая — $21 вход, $168 выход за миллион токенов
Заключение
GPT-5.2 представляет значительный шаг вперёд в профессиональном использовании AI. Это первая модель OpenAI, работающая на уровне или выше человека-эксперта в реальных задачах работы со знаниями. 70.9% побед над профессионалами в 44 профессиях демонстрирует что AI достигает экспертного уровня в широком спектре областей.
Рекордные результаты на программировании (55.6% SWE-Bench Pro, 80% SWE-bench Verified) делают GPT-5.2 мощным инструментом для разработчиков. Снижение галлюцинаций на 30% и улучшенная точность критичны для профессионального использования. Абсолютный максимум на AIME 2025 (100%) и первое преодоление 90% на ARC-AGI-1 показывают прогресс в математических рассуждениях.
Три версии модели позволяют выбрать оптимальный баланс между скоростью и качеством. Instant для быстрой ежедневной работы, Thinking для сложных задач требующих рассуждений, Pro для критически важных задач где максимальное качество стоит ожидания. Цена выше чем у GPT-5.1, но токен-эффективность компенсирует это для большинства использований.
Попробуйте GPT-5.2 в ChatGPT с платной подпиской или через API для разработчиков. Начать →
Часто задаваемые вопросы (FAQ)
Чем GPT-5.2 отличается от GPT-5.1?
GPT-5.2 превосходит GPT-5.1 по всем ключевым метрикам: 70.9% против 38.8% (GPT-5) на GDPval, 55.6% против 50.8% на SWE-Bench Pro, снижение галлюцинаций на 30% (6.2% против 8.8%), близко к 100% точности на длинном контексте до 256K токенов, ошибки зрения сокращены вдвое.
Сколько стоит GPT-5.2?
В ChatGPT подписка остаётся по той же цене. В API: gpt-5.2 — $1.75 за 1M входных токенов и $14 за выходные (против $1.25 и $10 у GPT-5.1). gpt-5.2-pro — $21 вход и $168 выход. 90% скидка на кэшированные входы. Несмотря на большую стоимость за токен, стоимость достижения качества ниже благодаря эффективности.
Какая разница между Instant, Thinking и Pro?
Instant — быстрая модель для ежедневной работы с улучшенным разговорным тоном. Thinking — для глубокой работы над сложными задачами с детальными рассуждениями (70.9% на GDPval). Pro — самый умный вариант для критически важных задач (74.1% на GDPval, 93.2% на GPQA), стоит дороже но даёт максимальное качество.
Когда GPT-5.2 станет доступна?
GPT-5.2 начала раскатываться 11 декабря 2025 в ChatGPT для платных планов (Plus, Pro, Go, Business, Enterprise). В API доступна сегодня для всех разработчиков. OpenAI развёртывает постепенно для плавности — если не видите сразу, попробуйте позже.
Работает ли GPT-5.2 с русским языком?
Да, GPT-5.2 поддерживает русский язык. Модель обучалась на многоязычных данных. Все три версии (Instant, Thinking, Pro) работают с русским языком для создания текстов, программирования, анализа документов, ответов на вопросы. Качество сопоставимо с английским для большинства задач.
Что будет с GPT-5.1?
В ChatGPT GPT-5.1 будет доступна платным пользователям три месяца под legacy моделями, затем будет удалена. В API OpenAI не планирует deprecated GPT-5.1, GPT-5 или GPT-4.1 и сообщит о любых планах с достаточным уведомлением для разработчиков.
Насколько GPT-5.2 точнее предыдущих версий?
GPT-5.2 Thinking показывает 6.2% ответов с ошибками против 8.8% у GPT-5.1 Thinking — снижение на 30%. На длинном контексте близко к 100% точности на 4-needle MRCR до 256K токенов. На GDPval 70.9% побед над профессионалами против 38.8% у GPT-5. Ошибки зрения сокращены вдвое.
Можно ли использовать GPT-5.2 для коммерческих проектов?
Да, GPT-5.2 доступна для коммерческого использования через ChatGPT (платные планы) и API. В API модель доступна всем разработчикам. Цены: $1.75 за 1M входных токенов, $14 за выходные (90% скидка на кэш). Для enterprise OpenAI предлагает Business и Enterprise планы с дополнительными гарантиями.
Как GPT-5.2 сравнивается с Claude и Gemini?
GPT-5.2 устанавливает новые рекорды: 70.9% на GDPval (профессиональные задачи), 55.6% на SWE-Bench Pro, 100% на AIME 2025, 90.5% на ARC-AGI-1. Это первая модель OpenAI на уровне эксперта в реальных задачах. Claude 3.5 и Gemini 2 сильны в разных областях, но GPT-5.2 показывает лидерство на профессиональных метриках.
Будет ли GPT-6 после GPT-5.2?
OpenAI не анонсировала GPT-6. Номер 5.2 указывает на улучшение в рамках поколения GPT-5. OpenAI фокусируется на постепенных улучшениях с сохранением номера поколения. Следующее крупное обновление может называться GPT-5.3 или сразу GPT-6 — пока неизвестно. GPT-5.2 построена с NVIDIA и Microsoft на Azure с GPU H100, H200, GB200-NVL72.
Илья Бердыш
12 дек. 2025 г.





